The Dialectical Agent: From Pipeline Architecture to Fine-Tuned Debate Model
The Dialectical Agent: From Pipeline Architecture to Fine-Tuned Debate Model
Debate is one of the most demanding reasoning tasks we can ask of a language model. A debater must construct coherent multi-minute speeches, select evidence from a fixed corpus, track which arguments have been dropped or refuted across a multi-turn exchange, and adapt strategy in real time based on what the opponent has said. No single LLM call can do this reliably.
This post describes two interconnected research contributions: (1) the Dialectical Agent Harness — a LangGraph-orchestrated, multi-stage pipeline that decomposes debate into tractable subtasks — and (2) a multi-phase fine-tuning curriculum that teaches a 30B-parameter mixture-of-experts model (Qwen3-30B-A3B) to execute this pipeline with increasing autonomy.
Part 1: The Pipeline Architecture
Why Decompose Debate?
A single prompt like "generate a 3-minute affirmative constructive speech" fails in predictable ways: the model hallucinates evidence, ignores strategic considerations, and produces generic rhetoric rather than specific clash. Our key insight is that debate speeches are the product of a reasoning process that can be decomposed into four distinct cognitive tasks, each with its own failure modes and quality signals.
Debate Preparation: The Belief Tree
Before a single word is spoken, the system builds an epistemological map of the resolution. This isn't prompt engineering — it's a formal Bayesian structure where every belief carries a credence value (degree of confidence between 0 and 1), and those credences must satisfy probability axioms.
The BeliefRefiner takes a topic and recursively decomposes it into a belief tree:
- Values — The foundational commitments at stake (e.g., "individual liberty" vs. "collective welfare")
- D1 Beliefs — Top-level claims for or against the resolution, each with a prior credence
- D2 Sub-Beliefs — More specific propositions that support or undermine D1 beliefs
- Arguments — Claim-Warrant-Impact structures generated from leaf beliefs
- Evidence — Specific evidence cards from our 90K-card Weaviate corpus, linked with stance detection (supports/opposes)
Each node in this tree carries a numeric credence — tracked internally as log-odds for numerical stability — and beliefs are connected by probabilistic dependency relationships: P(A|B) and P(A|¬B). This means the tree isn't just a taxonomy; it's a Bayesian network where updating one belief propagates to its dependents via Jeffrey conditionalization.
Once the tree exists, PerspectiveBuilder creates side-specific views. Each debater (AFF or NEG) receives a perspective: a pruned subtree containing 2 top-level D1 beliefs with their full hierarchies — sub-beliefs, arguments, and evidence pointers. The perspective also filters by a minimum credence threshold, so low-confidence claims don't waste time in the skeleton.
A BeliefGapDetector then scans each perspective for under-supported claims — beliefs that lack evidence or arguments with missing warrants — and fills gaps with targeted research from the evidence corpus.
This is where the connection to HEXIS (Phase 2) becomes critical. These perspectives aren't delivered as text in a system prompt. In the full system, beliefs from the tree are encoded as M-states — implicit memory perturbations that reshape what the debater attends to, what evidence feels salient, what rhetorical strategies feel natural. The debater doesn't "know" their beliefs the way a RAG system retrieves facts. Their beliefs are dispositional — shaping perception before deliberation, like Aristotle's hexeis.
And at the end of a debate, the loop reverses: judges observe the exchange and update the belief tree. A BayesianUpdater converts debate outcomes into evidence — winning arguments strengthen the beliefs that supported them, losing arguments weaken theirs — using damped likelihood ratios to prevent overcorrection:
dampened_lr = 1 + (raw_lr - 1) × damping
new_log_odds = old_log_odds + log(dampened_lr)
Updates propagate through the tree via Jeffrey conditionalization, and a CoherenceChecker ensures the resulting credence distribution remains probabilistically valid (no range violations, no entailment inversions, no partition failures). After many debates across many topics, these accumulated credence updates produce nuanced, experience-grounded positions — the raw material for federated aggregation in Phase 3.
The Four-Stage Speech Pipeline
Every speech in our system passes through four stages, each implemented as a DSPy module with structured input/output signatures:
Stage 1: Tactic Selection — Given the debate state (flow study of standing arguments, prior speeches, judge preferences), select which tactical approach to take. For an affirmative constructive (AC), this might be "criteria-based framework with empirical advantages." For a 1AR, this might be "triage: extend strongest argument, concede weakest, turn opponent's evidence."
Stage 2: Skeleton Building — Given the selected tactics and the side's perspective (a structured belief tree with evidence pointers), construct an argument skeleton: an ordered list of claims with allocated time and evidence slots. This stage receives the full belief tree context, enabling arguments grounded in the prepared case.
Stage 3: Evidence Selection — Given the skeleton, select specific evidence cards from a frozen corpus (90K cards in Weaviate). Evidence is selected by semantic similarity but constrained by the skeleton's claim structure, preventing the common failure mode of "evidence dump" where cards are topically adjacent but logically disconnected.
Stage 4: Speech Generation — Given tactics, skeleton, and evidence, generate the final speech text. This is the only stage that produces natural language output; the prior three stages produce structured intermediate representations.

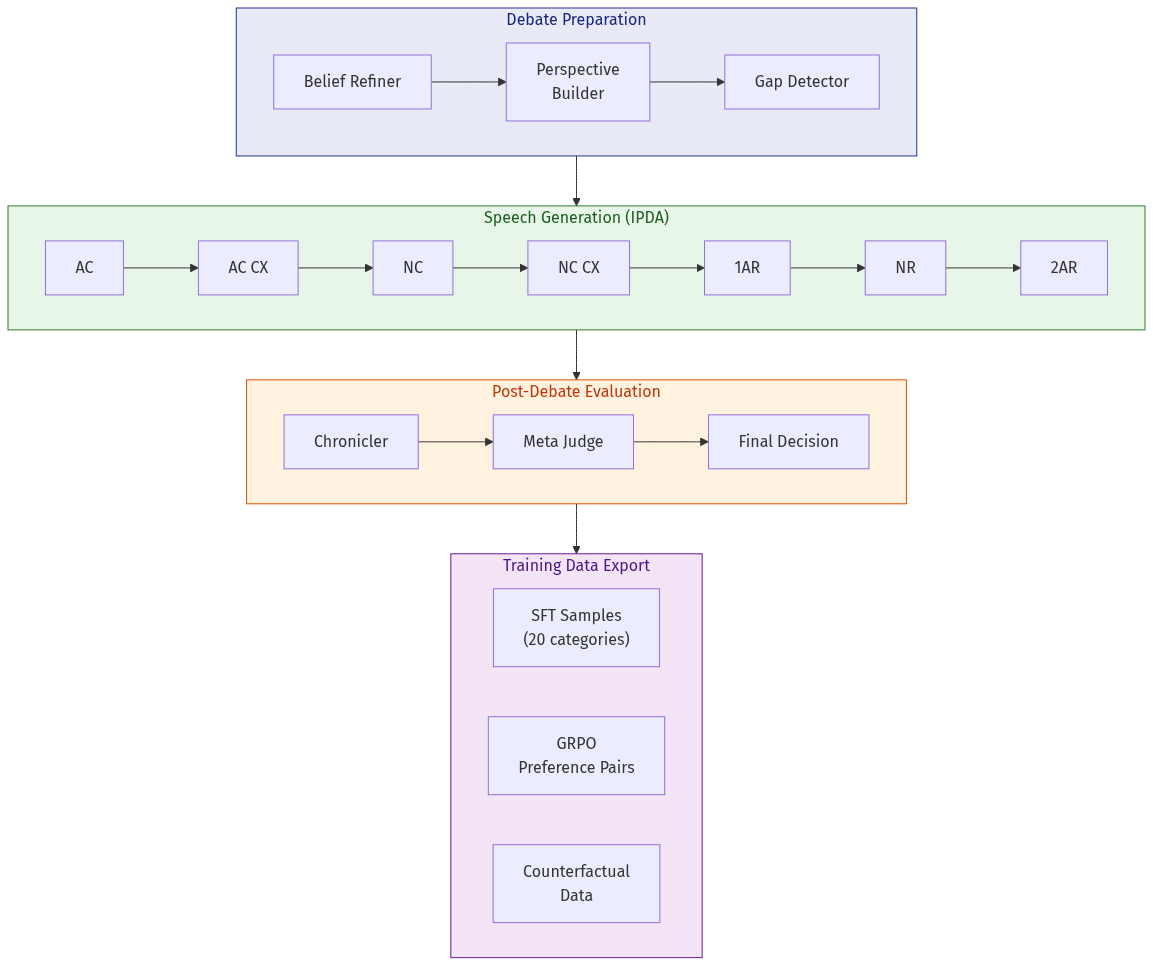
The LangGraph Orchestrator
The four-stage pipeline runs within a larger LangGraph state machine that manages the full IPDA (International Public Debate Association) format: seven speeches across two sides with cross-examination rounds.
Debate Preparation — Before any speeches, a BeliefRefiner generates a belief tree for the resolution, then PerspectiveBuilder creates AFF and NEG perspectives with evidence pointers. A BeliefGapDetector identifies under-supported claims and fills them with targeted research.
Flow Analysis — After each speech, a FlowStudy module analyzes the cumulative debate state: which arguments are standing, which have been attacked, which were dropped. This flow context is injected into the next speech's tactic selection, enabling genuine clash rather than ships-passing-in-the-night rhetoric.
Trial System & Judging — Each speech is generated multiple times (trials). A multi-tier judge ensemble scores each trial:
- Dimensional Judges score argument quality, evidence usage, clash engagement, and language
- Speech-Specific Dimensions apply IPDA-specific rubrics (e.g., AC is scored on prima facie case completeness, 1AR on triage efficiency, 2AR on crystallization clarity)
- Forensic Analysis attributes failures to specific pipeline stages
- Meta Judge detects systematic bias across the ensemble
The best trial is selected; if it falls below a quality threshold, the system retries with judge feedback or falls back to a stronger model (Claude Opus).
Branching — When trials produce divergent-but-high-quality speeches, the system can branch the debate tree, exploring counterfactual paths. This produces training data for what-if analysis: "if the 1AR had prioritized the economic argument instead of the moral one, how would the debate have unfolded?"
Cross-Examination
CX rounds use a separate graph that generates questions and answers in alternating turns. The questioner aims to extract concessions or expose inconsistencies; the answerer aims to protect their case structure. CX is particularly challenging because it requires real-time strategic reasoning about what information to volunteer versus withhold.
Dialectical Synthesis (Phase 8)
After a debate concludes, a dialectical synthesis module implements Hegelian dialectics: it identifies tensions between the AFF and NEG positions, generates novel synthesis premises that transcend the original binary, and can trigger split-debates for deeper exploration. This is our primary mechanism for knowledge discovery — using structured disagreement to find ideas that neither side started with.
Part 2: Fine-Tuning the Model
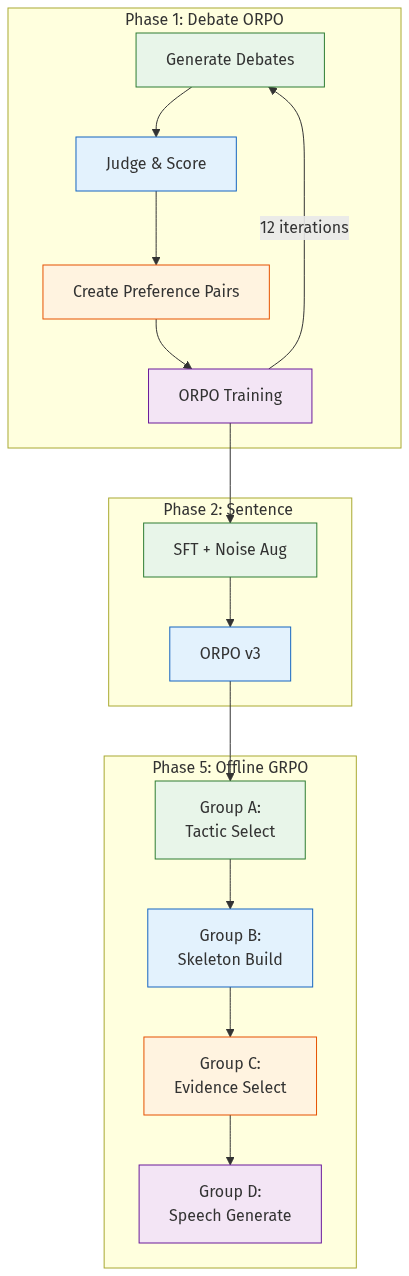
The Training Challenge
The pipeline above works well with frontier models (Claude Opus, GPT-4) at each stage. But our goal is a fine-tuned specialist that can run the pipeline on local or self-hosted infrastructure. We chose Qwen3-30B-A3B — a mixture-of-experts model with 30.5B total parameters but only 3B active per token — as our base. It's efficient enough to serve on a single A100-80GB while being capable enough for complex reasoning.
The training challenge: each debate contains ~33 individual LLM calls across 4 stages and 7 speeches. Training the model to improve at the debate level requires credit assignment across these calls — which individual decisions led to a better or worse debate outcome?
Phase 1: Debate ORPO (Iterative)
Method: Generate debates with the current model, judge them, create preference pairs (winning speech vs. losing speech for the same debate position), train with ORPO (Odds Ratio Preference Optimization).
Key finding: Iterative self-play works. Over 12 iterations (47 hours on 8xA100):
| Iteration | Mean Score | Best Score | Zero Rate |
|---|---|---|---|
| 1 (baseline) | 0.198 | 0.85 | 18.2% |
| 4 | 0.261 | 0.90 | 15.8% |
| 8 (peak) | 0.303 | 0.93 | 13.8% |
| 12 (plateau) | 0.285 | 0.89 | 13.5% |
The model improved 53% from baseline, then plateaued. Later iterations showed diminishing returns and slight regression — a common pattern in self-play where the model overfits to its own weaknesses.
Phase 2: Sentence Selection Training
Evidence selection is our highest-leverage stage. The model must select specific sentence IDs from evidence cards — a constrained output that prevents hallucination but demands precise reading comprehension.
Challenge: The base model had only 11.1% F1 on sentence selection. Worse, it exhibited severe positional bias — always selecting the first few sentences regardless of content.
Solution: SFT with noise augmentation (shuffling sentence order in training data) broke the positional bias. ORPO with format-consistent pairs (critical: chosen/rejected must have identical formatting, including thinking blocks) pushed further.
| Stage | F1 Score | Improvement |
|---|---|---|
| Base model | 0.111 | — |
| SFT + noise augmentation | 0.339 | +206% |
| ORPO v3 (format-consistent) | 0.379 | +241% total |
Critical bug discovered: Two failed ORPO runs taught us that preference pairs must have identical format. If the chosen example includes <think> blocks and the rejected doesn't (or vice versa), the model learns to distinguish them by format rather than content quality.
Phase 3: Cross-Examination
CX training used 58,565 generated exchanges filtered to 2,327 high-quality preference pairs. Scenario-based training (aggressive questioner, evasive answerer, etc.) produced a model that could both probe and defend across CX styles.
Phase 5: Offline GRPO (Group-Based)
Our most sophisticated training phase decomposes the pipeline into four training groups, each targeting a specific stage:
| Group | Stages | Improvement |
|---|---|---|
| A | Tactic Selection | +8.4% accuracy |
| B | Skeleton Building | +3.1% accuracy |
| C | Evidence Selection | +1.7% accuracy |
| D | Speech Generation | +14.3% accuracy |
Offline Group Relative Policy Optimization (GRPO): Rather than on-policy generation, we use pre-generated debates with captured logprobs. For each call, we compute advantage relative to other calls of the same type within the same debate group. This enables per-stage credit assignment: a bad debate score can be attributed to poor tactic selection (Group A) vs. poor speech generation (Group D).
The iteration pipeline follows a strict sequence: Opus golden samples → score all → SFT on top scores → merge → generate trials with SFT+ model (capturing logprobs) → score → GRPO → merge → next group.
Deployment
The final fine-tuned model is deployed on Modal with vLLM:
- Model:
dgonier/ipda-iter3-grpo-final(Qwen3-30B-A3B MoE) - GPU: A100-80GB with GPU memory snapshots for fast cold starts
- Scale-to-zero: 5-minute idle timeout
- API: OpenAI-compatible endpoint
The model serves all four pipeline stages through a single deployment, with DSPy handling structured output parsing for the intermediate stages.
Key Lessons
-
Decomposition beats prompting. A 4-stage pipeline with structured intermediates consistently outperforms single-call generation, even with frontier models. The pipeline makes failures attributable — you know which stage broke.
-
Format consistency in preference data is non-negotiable. Two failed ORPO runs taught us this the hard way. The model is a master at finding shortcuts.
-
Flow tracking enables genuine clash. Without explicit argument flow analysis between speeches, models produce parallel monologues. The FlowStudy module is what makes the debates actually debates.
-
Credit assignment requires decomposition. Group-based GRPO lets us train each pipeline stage independently with per-stage advantage estimation. Speech generation (Group D) had 4x the improvement of evidence selection (Group C).
-
Iterative self-play has diminishing returns. 8 iterations was our sweet spot. Beyond that, the model overfits to exploiting its own judge's biases.
Next in this series: HEXIS: Implicit Memory for Language Models — how we gave these debate agents persistent experiential dispositions that shape their reasoning without explicit retrieval.